Definition
An item of stock is any item held by the library that is available to the public, and catalogued in the library management system. This dataset is a summary of the different types of items held by libraries.
How the data can be collected
Library management systems will have the means of extracting and reporting data, and so this collection should be able to be automated. This may include automation that also publishes the data at regular intervals.
Sample data row
| Local authority | Library name | Count date | Type | Items |
|---|---|---|---|---|
| Barnet | Burnt Oak | 2019-10-07 | Adult audiobook | 208 |
A full sample can be viewed at Barnet stock summary.
Field notes
Type
The type will be the item type the item is categorised under in the library management system.
This should ideally be a human readable value rather than a code. For example ‘Adult Fiction’ rather than ‘ADU_FIC’. The set of types will be those that are used by each library service.
Potential problems
Non-standardised item types
Using item types as used by each library service will mean variation between similar types of items. For example one service may write ‘Child Fiction’ and another ‘Fiction - Child’.
How the data is updated
As the data is a ‘snapshot’ of the current count of items in a library catalogue, it would be easiest for the library services to publish a new file every time they do this count.
How the data could be used
Locally
Analysing stock alongside loans data can provide useful insight into stock and demand.
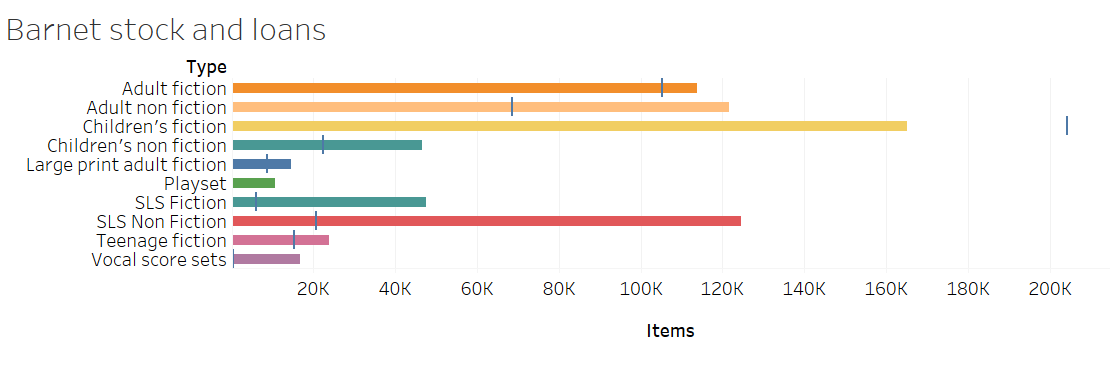
The above graph was created using Tableau, and used Barnet stock summary and loans to compare the two. This particular example highlights the high usage of Children’s Fiction items compared to amount of stock held.
Collection intelligence tools and analysis techniques can be shared between library services.
Nationally
The summary data is powerful enough to compare the range of stock within different services. Combined with the loans dataset it will also allow library services to see how some stock may perform that they currently have many of.
Seeing the range of item types in different services will also be useful for comparing what library services stock. Previous National statistical collection methods have attempted to standardise stock into set categories, which causes loss of this information.
This is also a first step to publishing more detailed catalogue data, which could be used for more powerful purposes. A detailed stock dataset could be used for an openly available inter-library loans catalogue, and single platform for searching for items in libraries.
Future enhancements
Full catalogue detail
It is likely that the enhancements to this dataset would need an additional schema e.g. ‘stock detail’. This would provide more complete information on all the titles and items held by the library service such as:
- Title
- Author (where applicable)
- ISBN (where applicable)
- Date acquired
- Date published
- Checkout status or item status (missing, withdrawn, on loan…)
- Count of loans
As well as providing detailed insight into catalogues across the country, workshops could be held on cleaning and refining the data held in library catalogues.